Abstract
We introduce TableLLM, a robust large language model (LLM) with 8 billion parameters, purpose-built for proficiently handling tabular data manipulation tasks, whether they are embedded within documents or spreadsheets, catering to real-world office scenarios. We propose a distant supervision method for training, which comprises a reasoning process extension strategy, aiding in training LLMs to understand reasoning patterns more effectively as well as a cross-way validation strategy, ensuring the quality of the automatically generated data. To evaluate the performance of TableLLM, we have crafted benchmarks tailored to address both document and spreadsheet formats as well as constructed a well-organized evaluation pipeline capable of handling both scenarios. Thorough evaluations underscore the advantages of TableLLM when compared to various existing general-purpose and tabular data-focused LLMs.
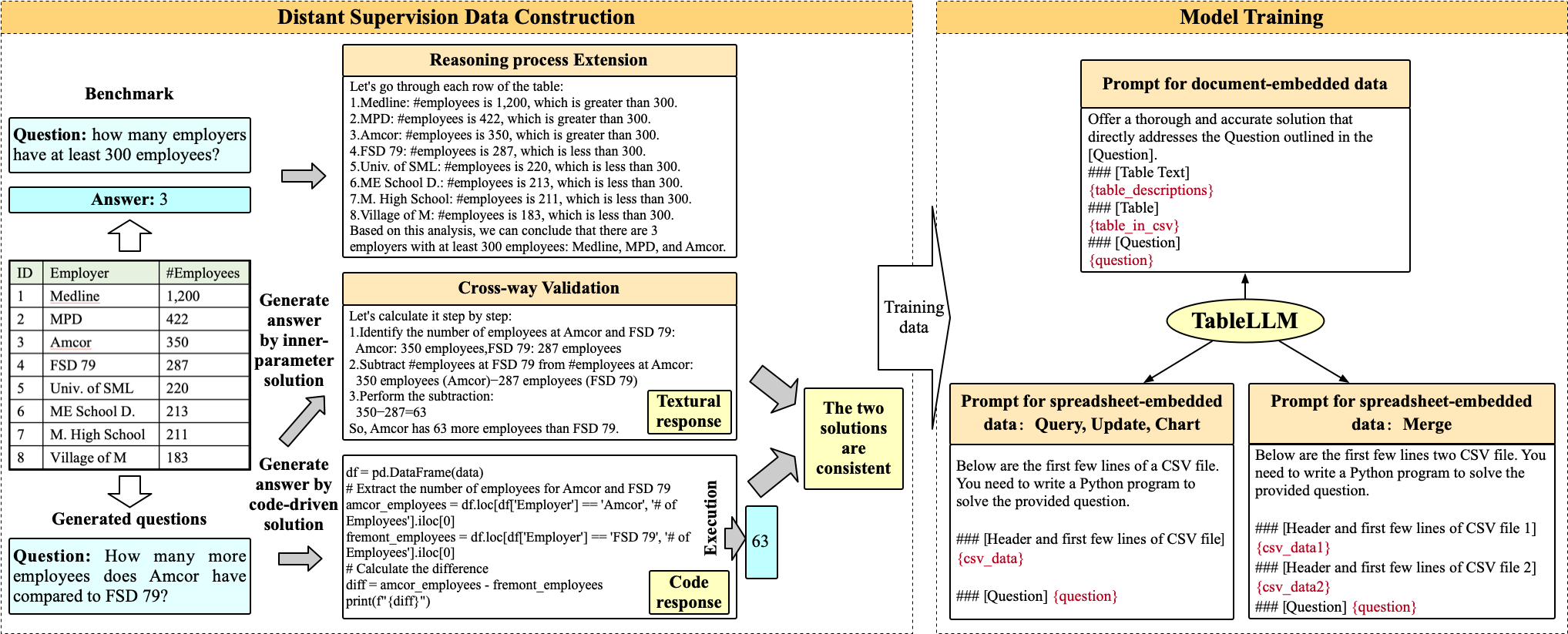
Overview
Evaluation Results
We evaluate the code solution generation ability of TableLLM on three benchmarks: WikiSQL, Spider and Self-created table operation benchmark. The text answer generation ability is tested on four benchmarks: WikiTableQuestion (WikiTQ), TAT-QA, FeTaQA. The evaluation result is shown below:
| Model | WikiTQ | TAT-QA | FeTaQA | WikiSQL | Spider | Self-created | Average |
|---|---|---|---|---|---|---|---|
| TaPEX | 38.5 | – | – | 83.9 | 15.0 | / | 45.8 |
| TaPas | 31.5 | – | – | 74.2 | 23.1 | / | 42.9 |
| TableLlama | 24.0 | 22.2 | 20.5 | 43.7 | 9.0 | / | 20.7 |
| TableGPT2(7B) | 77.3 | 88.1 | 75.6 | 63.0 | 77.3 | 74.4 | 76.0 |
| Llama3.1(8B) | 71.9 | 74.3 | 83.4 | 40.6 | 18.8 | 43.2 | 55.3 |
| GPT3.5 | 58.5 | 72.1 | 71.2 | 81.7 | 67.4 | 77.1 | 69.8 |
| GPT4o | 91.5 | 91.5 | 94.4 | 84.0 | 69.5 | 77.8 | 84.8 |
| CodeLlama (13B) | 43.4 | 47.2 | 57.2 | 38.3 | 21.9 | 47.6 | 43.6 |
| Deepseek-Coder (33B) | 6.5 | 11.0 | 7.1 | 72.5 | 58.4 | 73.9 | 33.8 |
| StructGPT (GPT3.5) | 52.5 | 27.5 | 11.8 | 67.8 | 84.8 | / | 43.1 |
| Binder (GPT3.5) | 61.6 | 12.8 | 6.8 | 78.6 | 52.6 | / | 36.3 |
| DATER (GPT3.5) | 53.4 | 28.4 | 18.3 | 58.2 | 26.5 | / | 33.0 |
| TableLLM-8B (Ours) | 89.1 | 89.5 | 93.4 | 89.6 | 81.1 | 77.8 | 86.7 |
Contact
If you have any questions, we encourage you to either create Github issues or get in touch with us at zhang2718@ruc.edu.cn, luosijia0906@ruc.edu.cn or zhang-jing@ruc.edu.cn.